[学習フェーズ]
サーバーやNW作業時には、サーバー負荷やログを適切に監視しながら進めることが重要です。特に本番環境や重要なサービスに対する操作では、事前・作業中・事後で状態確認を行うことがトラブル防止につながります。
作業前は事前のサーバー状態を確認しておきましょう。
設定変更作業後に異常が確認された場合、「事前はどうだったのか」が重要となります。
例えば、以下の3ケースを考えてみましょう。
ケース1)
作業前:CPU使用率が90%
作業事後:CPU使用率が91%
➡この場合、作業によるCPU変動はほとんど起こらなかったと言えます。
ケース2)
作業前:CPU使用率が50%
作業事後:CPU使用率が91%
➡この場合、作業によるCPU変動が大きく、設定変更内容にバグやエラーが起こっていると判断できます。
そのため、切り戻し判断(作業前の状態に戻す)が可能です。
ケース3)
作業前:未取得
作業事後:CPU使用率が91%
➡この場合、事前の状態が不明であるため、CPU91%が作業起因かどうか判断ができなくなってしまいます。
以上より、作業前と後の情報は重要であることがわかります。
また、作業中も常時監視ログをチェックしておきます。
これはミスや異常が起こった際に、いち早く障害に気づくためです。
作業は30分~1時間、長い場合は3時間ほど掛かる作業もあります。
その間も他サーバーや作業対象サーバーに異常ログが出ていないか確認が必要です。
ここからは、それぞれのフェーズにおける具体的なコマンドを紹介します。
事前確認(作業前)
作業前にサーバーのリソース状況を確認し、既に高負荷になっていないかを把握します。
作業内容にもよりますが、CPUやメモリ、ストレージ、トラフィック量などを確認しておきます。
free -h(メモリ使用量の確認)free -h➔ 使用中メモリ、空きメモリ、バッファの状況を確認。top(CPU・メモリのリアルタイム監視)top➔ 負荷状況を確認し、特に「%CPU」「%MEM」の高いプロセスに注意。
ポイント
常に「負荷がどれくらいなら作業を進めても安全か」の基準を意識すること。
作業中
作業中は、エラーや警告が発生していないかを確認するためにログを常時監視します。
tail -f(ログファイルの追跡表示)
tail -f /var/log/messages
➔ システム全体のログをリアルタイムで確認。
よく使うログファイル例
- システムログ:
/var/log/messages - 認証ログ:
/var/log/secure - Apacheアクセスログ:
/var/log/httpd/access_log - Apacheエラーログ:
/var/log/httpd/error_log
補足
特定のキーワードだけを抽出したい場合は grep と組み合わせる。
tail -f /var/log/messages | grep "error"
作業時は、複数のターミナルを立ち上げてログを確認しながら作業を行います。
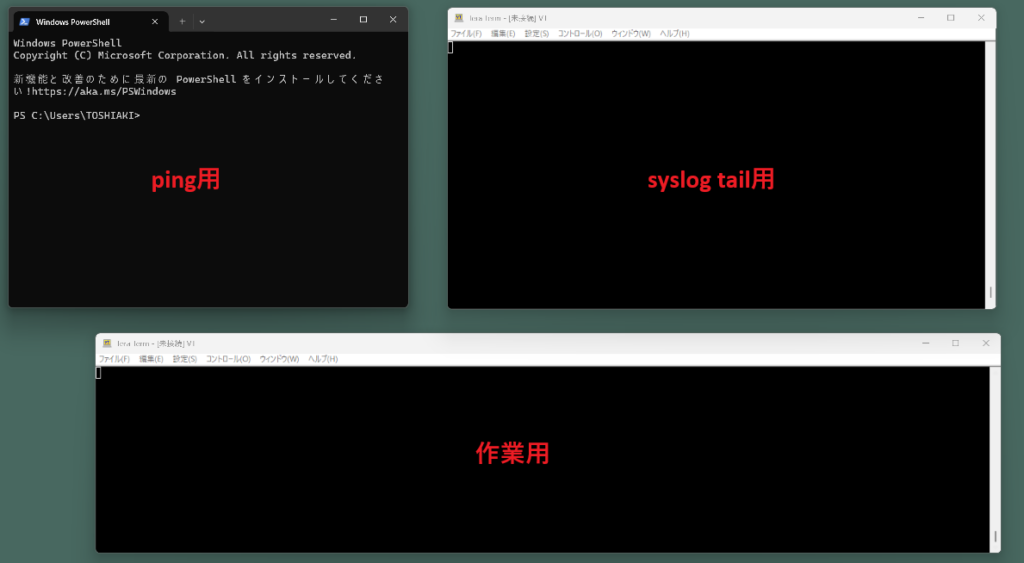
ping用:対象機器との疎通を常時確認
syslog tail用:syslogサーバーや対象サーバーのログをtailコマンドで表示
作業用:実際に作業を行うターミナル
※注意
複数のターミナルを立ち上げて作業を行うと、誤って別のターミナルにコマンドを打ち込む場合があります。
オペレーションミスとなるため注意しましょう。
事後確認(作業後)
作業完了後に、サーバーの状態が安定しているかを再確認します。特に、作業によってプロセスが暴走していないか、リソースが枯渇していないかをチェックします。
ポイントとしては、事前と同じコマンドを実施し、値に変化がないか(想定通りか)を確認します。
free -h topなど- チェックポイント
- メモリが極端に減っていないか。
- CPU使用率が異常に高騰していないか。
- 新たなエラーログが発生していないか。
企業によっては、コマンドログを事前・事後で張り付けをする手順を入れている場合もあります。
[実践フェーズ]
EC2でtailコマンドを使ったリアルタイムログ監視をしてみましょう。
■ 前提条件
- EC2インスタンス:Amazon Linux 2023
- Tera TermなどのSSHクライアントで2つのターミナルを接続(今回はターミナル1,ターミナル2と呼びます)
ターミナル1:ログ監視の準備
まずはターミナル1で、システムログをリアルタイムで監視します。
sudo tail -f /var/log/messages
ターミナル2:ログを発生させるコマンドを実行
次に、ターミナル2で意図的にログを発生させます。ここでは、失敗するコマンド や systemctl操作 を使ってログ出力を確認します。
■ ログ発生例①:存在しないコマンドを実行
hogehoge
➡ 「command not found」のエラーが /var/log/messages に出力されることがあります(環境による)。
■ ログ発生例②:systemctl でサービス操作
もっと確実にログを出す方法として、サービス操作を行います。
sudo systemctl restart sshd
➡ SSHサービスを再起動すると、システムログに「サービス再起動」の記録が残ります。
ターミナル1でログ出力を確認
ターミナル1で、ターミナル2の操作に応じて以下のようなログが流れることを確認します。
例:
Apr 28 11:00:00 ip-xxx-xxx-xxx systemd: Stopping OpenSSH server daemon...
Apr 28 11:00:00 ip-xxx-xxx-xxx systemd: Starting OpenSSH server daemon...
■ 補足:確認後の操作
Ctrl + Cでtail -fを終了します。