サーバー障害はサーバー、プログラム、ユーザー起因など様々な原因があります。
本章では、よくあるトラブル事例ごとに「まず確認すべきこと」を紹介します。原因切り分けの思考法も併せて身につけましょう。
ユースケース① サイトの表示異常
Webサイトが正常でない場合、まずは画面の状況から切り分けが可能です。
プログラミング言語・フレームワークのページが表示されている
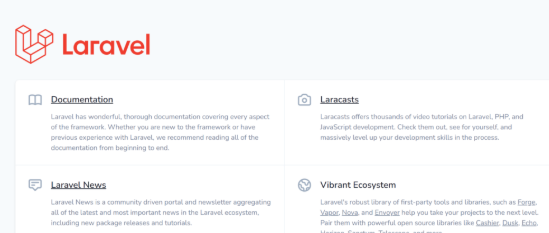
プログラミング言語・フレームワークのページが表示されている場合、プログラム側の起因である可能性が高くなります。
インフラエンジニアの場合は、フロント・バックエンドエンジニアにエスカレーションをしましょう。
ミドルウェアのページが表示されている
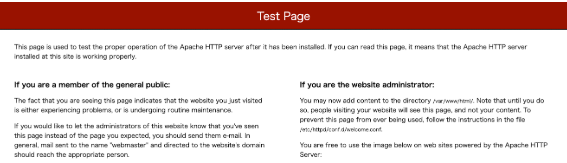
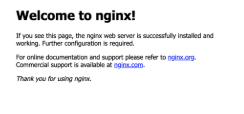
NginxやApacheのウェルカムページが表示されている場合、プログラムがそもそも動いていないなどの原因が考えられます。
もしくは、ミドルウェアの設定に誤りがあるかもしれません。
404/503エラー
HTTPレスポンスが表示されている場合は、以下を考えましょう。
400番台:クライアント側エラー
500番台:サーバー側エラー
ユースケース② サイトが表示されない(接続エラー)
500番台エラー、ずっと読み込み中など、サイトが表示されない場合は以下を調査します。
※ただし、サーバーがいつから起動しているか(安定しているか)、直近で設定変更作業があったかにより確認箇所は変わってきます。
想定原因
- ミドルウェアの停止
- セキュリティグループ or ファイアウォール設定ミス
- ポート未開放
対応コマンド
sudo systemctl status httpd
sudo ss -ltnp | grep :80
sudo firewall-cmd --list-all
ユースケース③サイトは表示されるが極端に遅い
想定原因
- CPU使用率が高騰している
- メモリ不足(スワップ発生)
- アクセス集中(負荷)
- AWSの場合は、EC2---RDS間でAZが違う
対応コマンド
top
free -h
sudo tail -n 50 /var/log/httpd/access_log
補足
top で httpd プロセスがCPUを占有していないか確認。アクセスログで特定IPからの集中攻撃(DoS)が疑われる場合も。
AWSを利用している場合は、CloudWatchでCPU・Memory・HTTPカウントなどがGUIで閲覧可能です。
ユースケース④ 突然ディスク容量が逼迫
想定原因
- ログ肥大化
- 不要ファイルの蓄積
対応コマンド
df -h
du -sh /var/log/httpd/*
sudo logrotate -f /etc/logrotate.d/httpd
補足
ディスク容量不足はパフォーマンス低下やサービス停止を引き起こす重大要因。定期的なログ管理が重要です。
まとめ
障害対応は「まず何を疑うか」「どこから確認するか」が鍵です。以下の流れを意識しましょう。
- サービス状態確認(systemctl / プロセス / ポート)
- リソース確認(CPU / メモリ / ディスク)
- ログ確認(エラーログ / アクセスログ)
- アプリ・ネットワーク確認(Python / 外部連携など)
この手順を習慣化することで、トラブル時の対応速度と精度が向上します。